Plane Crash Data - Part 1: Web Scraping
Several months ago I stumbled across the Kaggle data set Airplane Crashes Since 1908. Since I couldn't find the data source, I searched the web for historical plane crash data and quickly found the web page http://www.planecrashinfo.com. On this site you can find various tables inside tables with lots of information on aviation accidents of the last century. What you also find is a nice exercise on web scraping to collect the data on the web by your own.
This is what I'll do in part one of the plane crash series. The second part treats google maps API requests, here I'm going to retrieve the geo coordinates for the locations in the data set on plane crashes. In the last part of the series I will visualize the flight routes and the crash locations using the leaflet package in R.
# load required packages
library("dplyr")
library("xml2")
library("rvest")
library("tidyr")
library("magrittr")
In order to understand the structure of the website we are going to query, I advise you to go ahead and visit http://www.planecrashinfo.com, http://www.planecrashinfo.com/2016/2016 and for example http://www.planecrashinfo.com/2016/2016-1. The first site is the landing page. You find recent plane crashes and incidents there:

If you enter the second page, you can find data on all plane crashes happening in 2016:
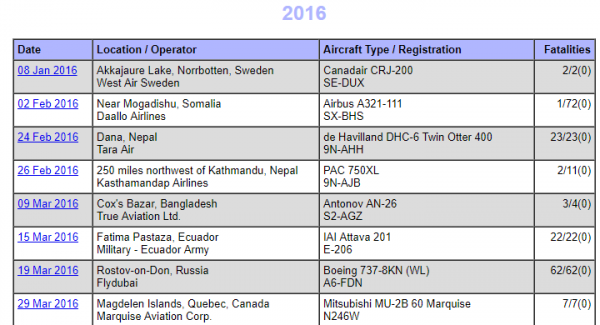
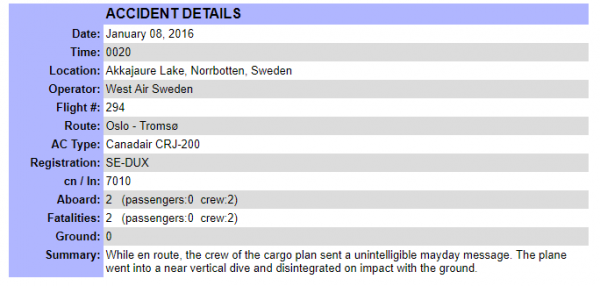
By adding a -1 to the url, you access the first entry in the table and get detailed information on that:
So, we first generate the URLs for the years 2014, 2015, and 2016.
# select from which years to get plane crash data and create URL for each
years <- c("2014", "2015", "2016")
urlYears <- paste0("http://www.planecrashinfo.com/", years,
"/", years, ".htm")
Next, we enter the table of the respective year, retrieve the number of entries in the table, and generate specific URLs for all entries.
# get URL for each plane crash table from each year selected
urls <- mapply(function(urlYear, year) {
rowNumber <- urlYear %>%
read_html %>%
html_table(header = TRUE) %>%
.[[1]] %>% nrow
urlsSpec <- paste0("http://www.planecrashinfo.com/", year,
"/", year, "-", 1:rowNumber, ".htm")
},
urlYears,
years
) %>% unlist
Now we can access the specific tables and retrieve the information.
# retrieve information
data <- lapply(urls, function(url) {
url %>%
# read each crash table
read_html %>%
html_table %>%
data.frame %>%
setNames(c("Vars", "Vals")) %>%
# header is a colunm and values are in a column -> tidy up
spread(Vars, Vals) %>%
.[-1]
})
We put together the list of data frames to one data set and choose appropriate variable names. We remove the colon and use lower case letters for the variable names.
# data list to data.frame and set appropriate variable names
data %<>%
bind_rows %>%
setNames(gsub(":", "", colnames(.)) %>% tolower)
Now we choose only the variables relevant for our analysis.
# pick relevant variables
data %<>% select(date, location, route, operator, aboard, fatalities)
Next, we want to clean up the strings contained in the location variable.
# clean location variable
data %<>% mutate(location = gsub("Near | near", "", location)) %>%
mutate(location = gsub(",.*,", ",", location))
Finally, we extract the number of people aboard by splitting the strings of the variable aboard and chosing the first element. We do the same with the variable fatalities in order to extract the number of people who died. Lastly, we calculate a ratio, giving us the percentage of people who died.
# extract total number of people aboard and fatalities
data$aboard <- strsplit(data$aboard, " ") %>%
lapply("[[", 1) %>%
as.numeric
data$fatalities <- strsplit(data$fatalities, " ") %>%
lapply("[[", 1) %>%
as.numeric
data$deathRate <- round((data$fatalities/data$aboard) * 100, 2)


